论文研读:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
省流版本:模拟人从粗看到细看的过程,设计了一个CNN based backbone,将模型理解图像的过程分为overview和focus两步,并且引入了根据全局上下文来动态生成卷积核参数的架构。
文章概览
之前的视觉神经网络大多采取了层级结构作为主干网络,从低到高提取特征,缺少一个显示top-down信号语义。 即便有用了top-down attention的网络也不适合作为主干网络,因为现有的方法大多还是用的循环神经网络的架构。
Therefore, how to develop a modern ConvNet that leverages the top-down attention mechanism while achieving an excellent performance-complexity trade-off remains an open problem.
作者提出了仿生的Deep-stage Decomposition Strategy(DDS),使用注意力机制来增强feature map和卷积核的权重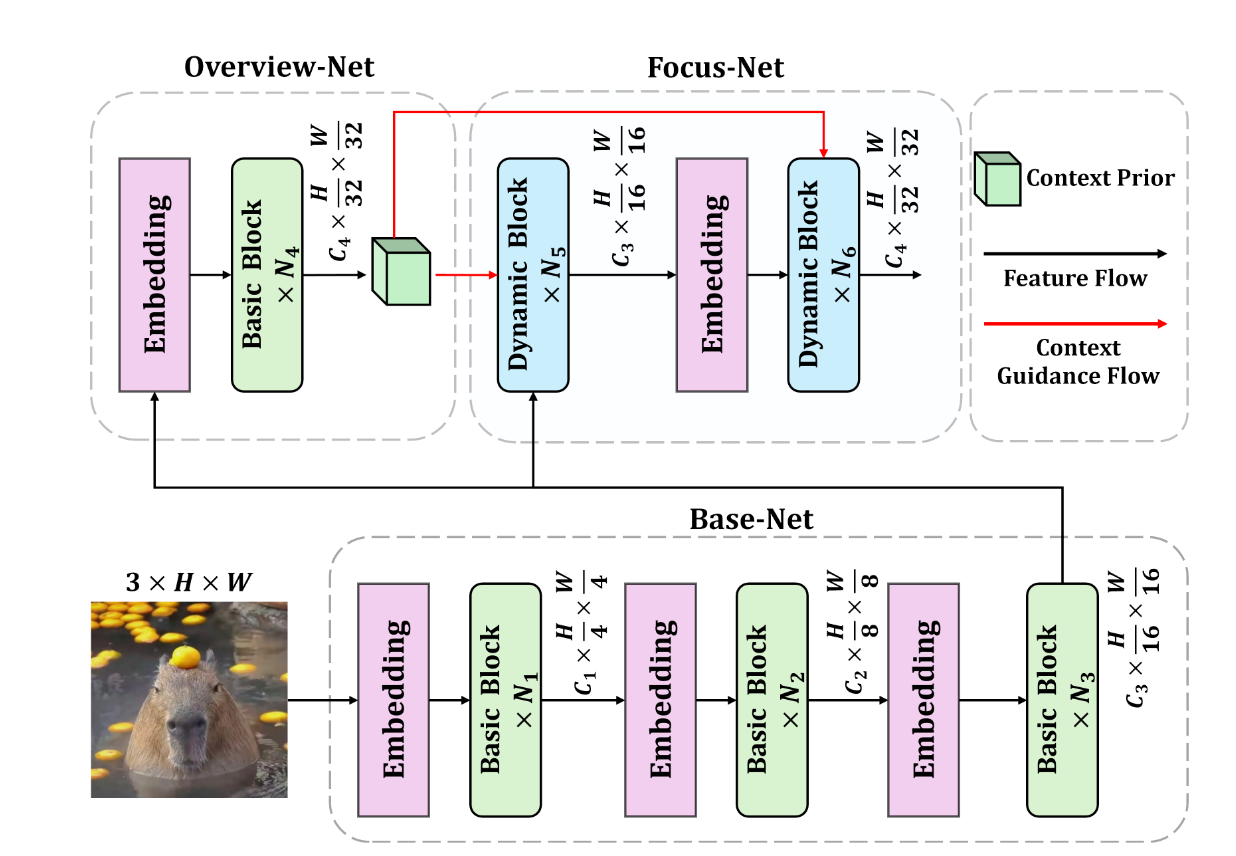 DDS将网络划分为三个部分,分贝是B
DDS将网络划分为三个部分,分贝是Base-net, Overview-net 和Focus-net
Basenet首先提取中低层次的语义信息,然后basenet的输出送入overview-net生成一个低质量的语义特征,模仿人类overview的过程。
把overview作为context prior,和Base net的输出一起送到一个更深的Focus-net里面,获取到更多的深层次语义变送hi。模仿人类look closely的过程。
其中的Focus-Net既要能够自适应地建模长距离依赖(modeling login-range dependencies)以产生大感受野,同时保留局部归纳偏置(local inductive biases)以捕捉细微的局部细节(nuanced local details)。
大核卷积核和动态卷积不像是Transformers或者Mamba(前者具有self-attention,后者是State Space model)擅长长距离建模。 虽然deformable卷积可以缓解这个我问题,但是牺牲了局部归纳偏执的能力。
为了解决这个问题,实现一个既要又要的模型(长距离依赖和局部归纳偏置),设计了一个新颖的Context-Mixing Dynamic Convolution(ContMix)。
对于Focus Net输入的每一个token(这里指的是feature map中某一个像素点),将这个像素点和region centers(从Overview模块中得到的Context prior中选取的区域中心)计算affinity,而非和所有的点都计算affinity
那么就得到了一个affinity map,吧affinity map送入到一个Linear Layer中,把Linear Layer的输出作为卷积核的权重,因此卷积核的内之和当前像素于全局的关系相关。
接着用这个卷积,进行卷积操作。 这样,因为卷积核中携带了global的信息,所以可以捕获长距离依赖关系。
有了上述的DDS(将网络拆分为Base0net/Overview-net和Focus-net三部分)和ContMix(用于再Focus-net中实现长距离依赖建模+局部归纳偏置)
模型设计
由Basenet生成中低级特征,然后将特征送入到Overview-net和Foucs-net中 overview-net生成一个context-prior,作为Focus-net的上下文先验。
在训练的时候,采用了双主干的设计:
- Base-net+Overview-Net
- Base-net+ Focus-net 在预训练阶段,各自都接了一个分类头,在Image-Net-1K上进行训练,采用相同的loss函数,分别学习特征的表示
在下游任务/推理阶段时,不需要Overview-net的分类头(移除辅助监督信号),因为在预训练中已经学会了如何提取overview
而且如果保留的话,会知识的训练过程变长
在分类任务里面,直接用Focus-net的输出作为预测
 chatGPT给我的年度诗篇 ```text
chatGPT给我的年度诗篇 ```text